How KIP-848 Moves Rebalancing to the Broker and Eliminates Group-Wide Pauses
Every Kafka developer has experienced it. You deploy a new consumer instance. A pod restarts. A node disappears.
Suddenly the entire consumer group pauses while Kafka performs a rebalance. For years, this behavior was considered normal.
With Kafka’s new Consumer Group Protocol (KIP-848), that assumption is no longer true. Kafka is moving rebalancing logic from clients to brokers, eliminating global synchronization barriers and significantly reducing disruption during scaling events. Apache Kafka 4.0 officially made the new protocol production-ready.
⚡ TL;DR (Quick Recap)
- Kafka 4.0 ships KIP-848 as GA: a broker-driven consumer rebalance protocol that replaces the old client-coordinated model.
- Rebalances are now incremental and partial — only the partitions actually moving are affected, not the whole group.
- Enable it per consumer with one config line: group.protocol=consumer. Most applications require no code changes.
- It’s optional for now, the classic protocol still works.
Why This Lands Now
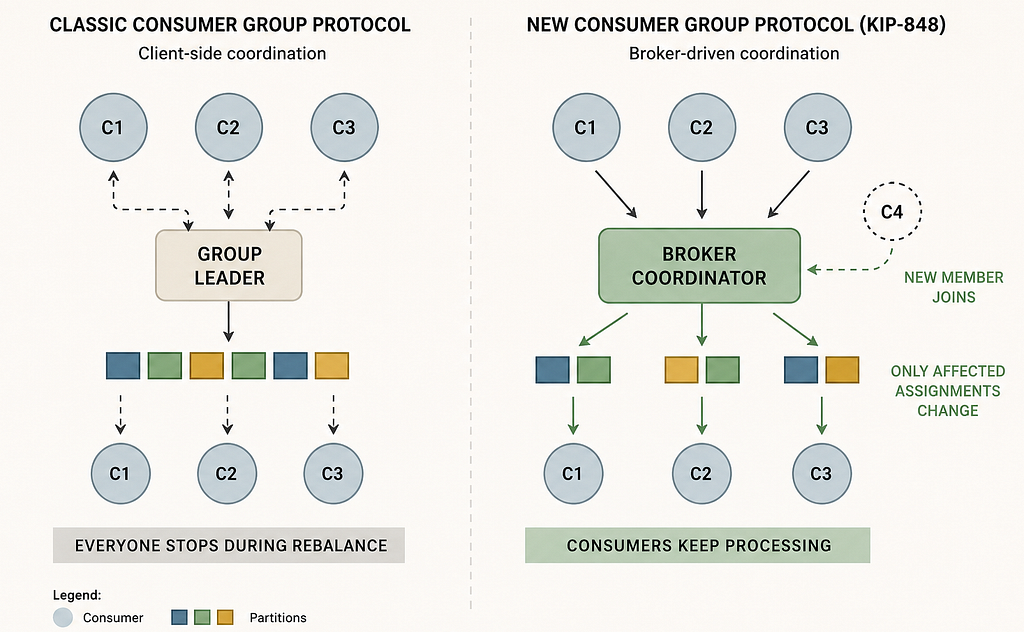
Kafka’s original consumer protocol asked clients to do too much work. One member was elected group leader, collected metadata from every other member, computed the partition assignment itself and pushed that plan back through the broker. That’s a lot of logic sitting in a client library that ships independently of the broker.
This created two recurring problems. First, every rebalance bug required a client upgrade to fix — painful in managed cloud environments where client adoption lags. Second, the “eager” version of the protocol made every membership change a synchronization event: all consumers stop, all partitions get revoked, then everyone rejoins. KIP-429’s cooperative rebalancing (Kafka 2.4, 2019) reduced unnecessary partition movement, but consumers still froze processing during the handshake itself.
KIP-848 doesn’t patch around that design — it replaces it.
What Actually Changed Under the Hood
The new protocol, internally called the “consumer” group protocol (versus the legacy “classic” one), restructures three layers at once:
- Coordination moves server-side. The broker’s group coordinator now owns partition assignment. Consumers simply declare what they’re subscribed to. They no longer compute assignments themselves.
- Heartbeats replace JoinGroup/SyncGroup. Instead of a multi-phase handshake, consumers send continuous heartbeats that double as the channel for acknowledging new or revoked partitions.
- Reconciliation is incremental. When membership changes, the coordinator only reassigns the partitions that need to move. Unaffected consumers never stop processing.
- The client got a new threading model. Network I/O and rebalance logic are separated from the application thread, making the client itself lighter and less prone to the bugs that plagued the old thick-client design.
Compared side by side, the practical differences are straightforward:
- Classic protocol: client-elected leader, full JoinGroup/SyncGroup round trip, assignment computed on the client, larger blast radius per change.
- Consumer protocol: broker-owned coordinator, heartbeat-based reconciliation, assignment computed on the server, blast radius limited to changed partitions only.
One limitation worth flagging early: custom client-side assignors aren’t supported yet under the new protocol (tracked in KAFKA-18327) and rack-aware assignment strategies aren’t fully implemented either (KAFKA-17747). If your team relies on either, check your specific use case before migrating.
Turning On the New Protocol
The broker side needs no extra work — Kafka 4.0 enables the consumer protocol on the coordinator by default. The opt-in lives entirely on the client.
Add this line to your consumer configuration:
# consumer.yml
spring:
kafka:
consumer:
group-id: order-service
properties:
group.protocol: consumer
# Under consumer protocol, the classic-group settings are ignored:
# session.timeout.ms
# heartbeat.interval.ms
# partition.assignment.strategy
Java configuration
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
// ... other standard properties ...
props.put("group.protocol", "consumer");
return new DefaultKafkaConsumerFactory<>(props);
}
That’s it for a minimal setup.
You can still rely on the broker-side equivalents: group.consumer.session.timeout.ms, group.consumer.heartbeat.interval.ms, and group.consumer.assignors.
If you have spring.kafka.consumer.partition-assignment-strategy set elsewhere, Spring Kafka logs a warning and ignores it under the new protocol.
Compatibility checklist before you flip the switch:
- Broker cluster running Kafka 4.0 or later (The consumer group protocol is implemented in the modern KRaft-based coordinator architecture and is not available on ZooKeeper-based clusters).
- Client library on kafka-clients 4.0+ (Java 11+ for clients; Java 17+ for brokers).
- No reliance on Consumer#enforceRebalance() — it's a no-op under the new protocol, enforceRebalance() was always a best-effort hint even in the classic protocol.
For migrating an existing group, you have two realistic paths: a rolling restart of consumers with the new config or stopping the group entirely and restarting it empty with the new protocol enabled. Kafka will auto-convert a group between classic and consumer behavior when it’s empty, so the empty-restart path is the simpler one if a brief pause is acceptable.
Why This Matters in Kubernetes
This section will resonate strongly with Spring Boot users.
Typical scenarios:
- Rolling deployments
- HPA scaling
- Spot instance interruptions
- Node replacements
Historically each of these events could trigger disruptive rebalances.
With the new protocol:
- unaffected consumers continue processing
- assignments move incrementally
- scaling becomes smoother
- consumer lag spikes are reduced
This is particularly valuable for large consumer groups with dozens or hundreds of partitions.
Final Takeaways
KIP-848 is the kind of change that doesn’t show up in feature demos, but matters enormously in production. It doesn’t add new APIs your code needs to learn — it removes a structural weakness that’s been costing teams latency and on-call hours since the early days of Kafka consumer groups.
The migration cost is low: one config line, a compatible broker and a compatible client. The main reason to wait is the current gap in client-side custom assignors and rack-aware strategies — if you depend on either, test thoroughly in a non-production cluster first.
For Spring Boot teams running Kafka in cloud-native environments, this may be one of the most important Kafka changes since cooperative rebalancing.
Originally posted on marconak-matej.medium.com.