[MM’s] Boot Notes — Spring Boot 4.0 and Kafka: Rethinking Message Consumption with Share Groups
Inside Share Groups: Why Your Next Kafka Consumer Doesn’t Need to Care About Partitions (and Gets Broker-Managed Retries).
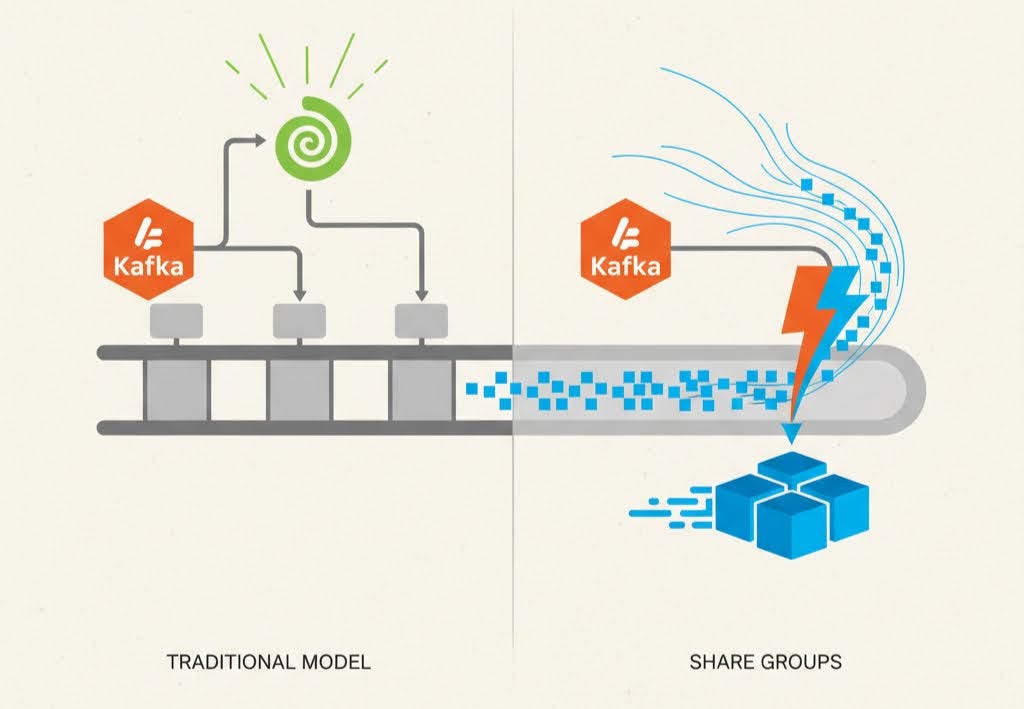
Every Kafka developer has been there: staring at a topic with hundreds of partitions, trying to squeeze more throughput out of a system that was designed for ordering. You scale partitions to match consumer count, tweak rebalance settings and still end up juggling complexity. It’s efficient, but inflexible.
Spring Boot 4.0 changes that equation with native support for Kafka Share Groups — a new model that breaks free from partition-based consumption. Instead of assigning partitions to consumers, Share Groups distribute individual records across all available consumers. Think of it as true queue semantics for Kafka, finally built into the platform.
⚡ TL;DR (Quick Recap)
- Share Groups distribute records, not partitions, enabling queue-like consumption patterns.
- Spring Boot 4.0 adds first-class support via familiar @KafkaListener APIs and Share Consumer factories.
- Concurrency control is built-in, allowing multiple consumer threads per instance.
- Three acknowledgment types — ACCEPT, RELEASE, and REJECT — provide broker-managed retry and poison message handling.
Why Partitions Became a Bottleneck
Traditional Kafka consumer groups provide partition-level ownership — each partition belongs to exactly one consumer. That’s great for ordered workflows, but a poor fit for independent workloads like image processing or background jobs. To increase throughput, you must increase partitions, which adds operational overhead and rebalancing complexity.
Want 100 parallel consumers? You need 100 partitions — and once they’re created, scaling down isn’t straightforward. Partitions are your concurrency ceiling. For many teams, that’s been Kafka’s hidden tax.
Share Groups: A New Consumption Model
Kafka 4.0 introduces Share Groups (KIP-932), and Spring Boot 4.0 brings them natively to the Spring ecosystem. Instead of assigning partitions to consumers, the broker distributes records dynamically among all active members of a share group.
Key differences at a glance:
- Traditional model: Assigns partitions → Share Groups: Distribute records
- Traditional: Consumers track offsets → Share Groups: Broker tracks record state
- Traditional: Apps handle retries → Share Groups: Broker manages redelivery and poison messages
- Traditional: Scaling triggers rebalancing → Share Groups: Add consumers seamlessly
The result? You get Kafka’s reliability with RabbitMQ-style flexibility.
When to Use (and Avoid) Share Groups
Share Groups aren’t a replacement for consumer groups — they’re complementary.
Use Share Groups when:
- Order doesn’t matter — e.g., image processing, notifications, job queues.
- Workload volume fluctuates and requires elastic scaling.
- Message processing time varies, and you want fair distribution.
- You need queue semantics with competing consumers.
Stick with traditional consumers when:
- You need strict ordering (transactions, session events).
- Building stateful stream processing or aggregations.
- Using Kafka Streams or maintaining partition-local state.
Implementing Share Groups in Spring Boot
Spring Boot 4.0 makes adoption simple — if you’ve used @KafkaListener, you already know the pattern.
Basic Configuration
@Configuration
public class KafkaShareConsumerConfig {
@Bean
public ShareConsumerFactory<String, String> shareConsumerFactory(KafkaProperties properties) {
Map<String, Object> props = properties.buildConsumerProperties();
// Share Groups don't support these properties - broker manages delivery
props.remove("isolation.level");
props.remove("auto.offset.reset");
return new DefaultShareConsumerFactory<>(props);
}
@Bean
public ShareKafkaListenerContainerFactory<?, ?> shareKafkaListenerContainerFactory(
ShareConsumerFactory<?, ?> shareConsumerFactory) {
return new ShareKafkaListenerContainerFactory<>(shareConsumerFactory);
}
}
Consuming Messages
@Component
public class DemoConsumer {
@KafkaListener(
topics = "${demo.kafka.topic}",
containerFactory = "shareKafkaListenerContainerFactory",
concurrency = "${spring.kafka.listener.concurrency}"
)
public void listen(ConsumerRecord<String, DemoEvent> record) {
log.info("Processing: {}", record.value());
}
}
By default, successful processing implies ACCEPT, and exceptions imply REJECT.
Fine-Grained Control with Explicit Acknowledgment
For transient failures or business rules that require manual decisions, enable explicit acknowledgment:
@Bean
public ShareConsumerFactory<String, String> explicitShareConsumerFactory(KafkaProperties properties) {
Map<String, Object> props = properties.buildConsumerProperties();
props.put(ConsumerConfig.SHARE_ACKNOWLEDGEMENT_MODE_CONFIG, "explicit");
return new DefaultShareConsumerFactory<>(props);
}
Listener with acknowledgment control:
@KafkaListener(topics = "demo-topic", containerFactory = "explicitShareKafkaListenerContainerFactory")
public void processPayment(DemoEvent event, ShareAcknowledgment ack) {
try {
if (!isValid(event)) {
ack.reject(); // permanent failure
return;
}
service.process(event);
ack.acknowledge(); // ACCEPT
} catch (TransientException e) {
ack.release(); // RELEASE - retry later
}
}
Three acknowledgment types:
- acknowledge() → ACCEPT
- release() → transient failure, retry allowed
- reject() → permanent failure, no retry
Scaling with Concurrency
Share Groups decouple parallelism from partitions. Spring Boot supports multiple consumer threads per container:
spring:
kafka:
listener:
concurrency: 6
Each thread acts as an independent consumer within the same share group. Scaling vertically (threads) or horizontally (instances) is additive. Five instances with concurrency 3 = 15 consumers in the same group.
No rebalancing. No topic partitions reconfiguration.
Broker-Managed Retries and Poison Messages
Share Groups introduce broker-managed redelivery. When a record is acquired, it’s locked for a time window (default 30s). If it’s not acknowledged, the broker returns it to the pool.
After a configurable number of attempts (group.share.delivery.attempt.limit, default 5), the broker moves the record to Archived state, preventing infinite retries.
var maxAttempts = new ConfigEntry("group.share.delivery.attempt.limit", "10");This makes application-level retry logic optional — the broker enforces safety.
Testing with Testcontainers
Spring Boot 4.0 integrates @ServiceConnection, making Kafka Testcontainers setup seamless:
@TestConfiguration(proxyBeanMethods = false)
public class TestKafkaConfiguration {
@Bean
@ServiceConnection
public ConfluentKafkaContainer kafkaContainer() {
return new ConfluentKafkaContainer(DockerImageName.parse("confluentinc/cp-kafka:8.1.0"))
.withEnv("KAFKA_GROUP_COORDINATOR_REBALANCE_PROTOCOLS", "classic,consumer,share")
.withEnv("KAFKA_SHARE_COORDINATOR_ENABLE", "true")
.withEnv("KAFKA_GROUP_SHARE_ENABLE", "true");
}
}
@SpringBootApplication
public class TestKafkaApplication {
public static void main(String[] args) {
SpringApplication.from(KafkaApplication::main)
.with(TestKafkaConfiguration.class)
.run(args);
}
}
Run locally with a full-featured Kafka broker — no mocks required.
Production Readiness & Compatibility
- Status: Early Access (Kafka 4.0), Preview (4.1), GA planned (4.2)
- Version constraint: Clients and brokers must share the same minor version.
- Limitations: No message converters or batch listeners yet; unacknowledged records block polls per-thread.
Share Groups and classic consumer groups can coexist in one cluster, even within the same Spring Boot app.
Migration Tips
- Audit your workloads — identify where ordering doesn’t matter.
- Adjust your acknowledgment strategy (RELEASE vs REJECT).
- Start with non-critical queues and use Testcontainers to validate behavior.
- Monitor archived record metrics to spot poison messages early.
Final Takeaways
Spring Boot 4.0’s support for Kafka Share Groups redefines parallel message processing. You no longer need to over-partition topics just to scale consumers. Share Groups deliver record-level distribution, built-in retries and concurrency flexibility — all with the same @KafkaListener simplicity.
If your workloads depend on throughput rather than order or if partition scaling has been a headache, this is the feature to watch. As Kafka 4.2 reaches GA, Share Groups will move from experimental to essential.
You can find all the code on GitHub.
Originally posted on marconak-matej.medium.com.